stb_truetype抗锯齿软件渲染器第二版工作原理
[原始标题:How the stb_truetype Anti-Aliased Software Rasterizer v2 Works]
[原文地址:http://nothings.org/gamedev/rasterize/]
[源代码地址:https://github.com/nothings/stb/blob/master/stb_truetype.h]
[无责任转载翻译。方括号内文字为个人笔记,不是原文。]
[rasterize/rasterization的翻译是光栅化,栅格化,或者像素化。rasterizer暂时翻译成渲染器]
Sean Barrett, 2015-07-15
Abstract 摘要
Previous versions of stb_truetype to 1.06 used a simple extension of the traditional scanline filling algorithm to compute horizontally-antialiased scanlines combined with vertical oversampling. The stb_truetype 1.06 algorithm (a re-invention of an algorithm generally credited to Levien’s LibArt) computes the exact area of the concave polygon clipped to each pixel (within floating point precision) by computing the signed-area of trapezoids extending rightwards from each edge, and uses that signed-area as the AA coverage of the pixel. This provides more accuracy than sampling, although it is incorrect when shapes overlap (as it measures the area of the shapes within the pixel, not the fraction of the pixel that the shapes obscure), and is slightly faster than the old algorithm.
stb_truetype 1.06版之前用的算法是传统扫描线填充算法的一个简单扩展,这个算法计算水平方向抗锯齿扫描线,并在垂直方向过采样。stb_truetype 1.06版用的算法(源自Levien的LibArt程序的算法的一次重新发明)计算凹多边形在每个像素里所占的精确区域大小(浮点数精度)。这个算法计算每条边向右扩展的梯形区域的有符号面积,以此作为像素的抗锯齿覆盖面积。这个算法比采样更为精确,比原先的算法也快一些,但在形状有重叠时会不正确(因为会计算这些形状的总面积,而不是这些形状覆盖的像素面积)。
[摘要第一次看完全懵逼。看完文章回过头看才明白。]
Traditional scan conversion 传统扫描转换
To determine if a point is within a concave-with-holes polygon, we classify each polygon edge with a direction (making each polygon a “winding”). Then, we cast a ray from the point to infinity, and count the edges it crosses, using a signed number for each edge (+1 in one direction, -1 in the other direction). If the final sum is non-zero, then the point is inside the polygon (assuming a non-zero fill rule).
为了判断一个点是否在一个凹且有洞的多边形内,我们给多边形的每一条边定一个方向,然后从这个点向无穷远投射一条射线,数一共穿过了多少条边。每条边根据方向不同+1或者-1。如果最终结果不是零,那么这个点就在多边形内(非零填充规则)。
[判断一个点是否在多边形内,参见wikipedia。射线法并不需要确定每条边的方向,穿过的每条边都+1,最终结果是偶数则点在多边形外,是奇数则点在多边形内(奇偶填充规则)。这里说的是非零填充规则,参见wikipedia。在多边形自身重叠的情况下,非零填充规则与奇偶填充规则得到的结果会有区别。TrueType字体遵循非零填充规则。SVG中可以选择nonzero或者evenodd填充方式]
The classic algorithm for filling such a polygon simply computes the same calculation incrementally.
用经典算法填充多边形就是简单的逐点增量的进行这个计算。
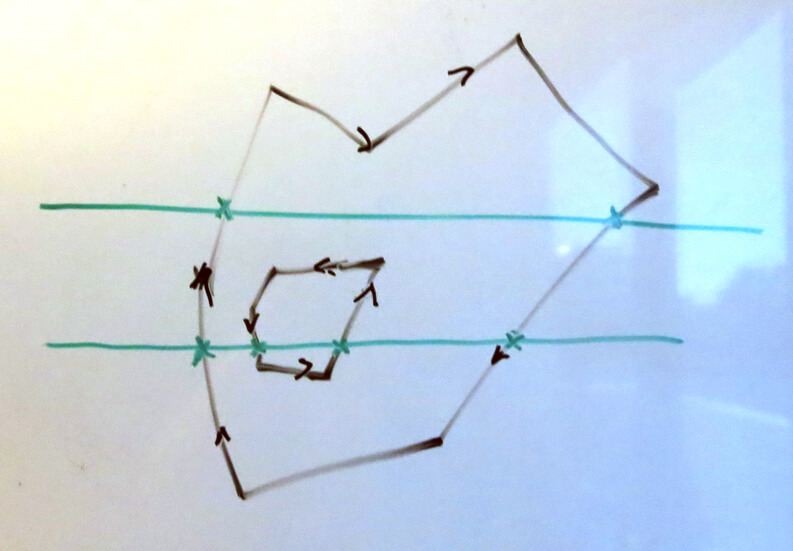
For any scanline (e.g. the green lines above), we can start at negative infinity (i.e. anywhere to the left of the polygon) and scan along the line, counting crossings. Whenever the crossing count goes from zero to non-zero, we begin a filled region; whenever it goes from non-zero to zero, we end a filled region. For a closed polygon, it will always end up zero if it started at zero. (There are various things one must be careful about, e.g. if a vertex falls exactly on a scanline, we must be careful how we count those edges as ‘crossing’ that scanline. These are engineering details that don’t affect the algorithm, and don’t actually require much or any code if the right conventions are used.)
对任一扫描线(上图绿色线),我们从负无穷(也就是多边形左边的任意位置)开始,沿扫描线计数穿过多少条边。当计数从零变为非零时,我们开始填充;当计数从非零变为零时,我们结束填充。对于闭合的多边形,开始时计数值为零,则最终结束时计数值也为零。(有许多细节需要考虑,如当多边形的一个顶点落在扫描线上时,我们必须考虑如何计数扫描线“穿过”了多少边。这些是不影响算法的技术细节,如果使用了合适的约定,并不需要多少代码来处理。)
To actually implement this, a typical algorithm is:
- Gather all of the directed edges into an array of edges
- Sort them by their topmost vertex
- Move a line down the polygon a scanline at a time, and for each scanline:
- Add to the “active edge list” any edges which have an uppermost vertex before this scanline, and store their x intersection with this scanline (because the edge list has been sorted by topmost y, edges from the edge list are always added in order)
- Remove from the active edge list any edge whose lowestmost vertex is above this scanline
- Sort the active edge list by their x intersection (incrementally, as it doesn’t change much from scanline to scanline)
- Iterate the active edge list from left to right, counting the crossing-number, and filling pixels as filled edges start and end
- Advance every active edge to the next scanline by computing their next x intersection (which just requires adding a constant dx/dy associated with the edge)
典型的算法实现是这样的:
- 把所有有方向的边放到一个数组里
- 按靠上的顶点的y坐标对这些边进行排序
- 从上到下对多边形逐行扫描,对于每条扫描线:
- 把所有靠上的顶点在这条扫描线之上的边加入“活跃边列表”,并存储它们和这条扫描线的交点的x坐标(由于边数组按靠上的顶点的y坐标排过序了,所以边是按顺序添加的)
- 从活跃边列表中移除所有靠下的顶点在这条扫描线之下的边
- 按交点x坐标对活跃边列表进行排序(增量的进行,因为各个扫描线之间变化不大)
- 遍历活跃边列表,计数交点,填充像素
- 计算并更新活跃边列表里每条边对下一条扫描线的交点x坐标(只需加一个与这条边相关的常数dx/dy)
Traditional scan conversion with 1D anti-aliasing 传统扫描转换 + 一维抗锯齿
For anti-aliasing, we want to know approximately how much of each pixel is covered by the polygon. For efficient implementation, we treat the pixel as a little square and literally just measure the coverage of that square; this is equivalent to using a box filter, which while not necessarily ideal is a reasonable trade-off of performance for quality. (Doing anything other than a box filter would be much, much more complicated.)
为了抗锯齿,我们想知道每个像素里有多大面积被多边形覆盖。为了高效的实现,我们把像素视为一个小的正方形,然后测量这个正方形的覆盖范围。这相当于使用了一个盒式滤波器。这可能并不完美,但这是对性能和质量的合理权衡。(任何其他方法都要复杂得多。)
[像素本来就是正方形的,像素被覆盖了多大面积,像素就有多深,很好理解。扯上滤波器感觉简单问题复杂化了。像素化相当于对多边形进行下采样,下采样用的滤波器不一定是box filter,高斯滤波什么的也行,没有抗锯齿就相当于用狄拉克δ函数进行下采样。是不是越扯越高大上了,哈哈。]
I’m not sure if I read this algorithm somewhere or if I (re-)invented it myself, but it is a pretty straightforward extension. In the above algorithm, we treat scanlines as infinitely-thin 1D lines, but then we only sample the crossing-count at (say) pixel centers, despite the fact that we have more information along the horizontal axis.
我不知道是我在哪儿看到过这个算法,还是我自己重新发明了这个算法,反正这个算法是上面算法的直接扩展。在上面算法中,我们认为扫描线是一维无穷细的。尽管在横轴上有更多的信息,我们只把交点采样在了像素中心。
[交点x坐标是一个小数,但上面算法是逐像素的,把交点x坐标作为整数处理,小数部分没用到,所以说有更多的信息没有利用。]
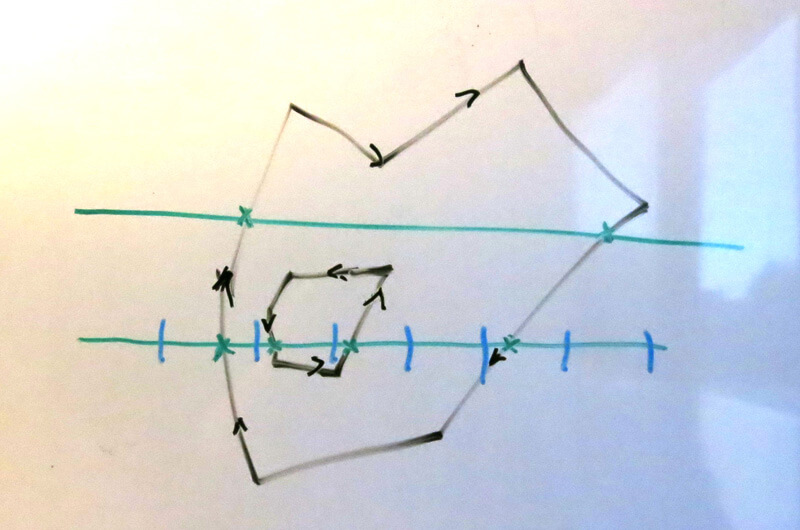
Here we’ve divided the lower “scanline” into multiple pixels, where each blue tick mark represents the boundary between pixels. We can easily measure how much of the scanline line segment between two pixels is “inside” the polygon, by coloring the parts of the line that are inside a different color:
下图中我们把扫描线切成了多个像素,蓝色标记了像素的边界。我们很容易测量一个像素的线段有多长在多边形里面。我们用不同的颜色标记出了在多边形里的线段:
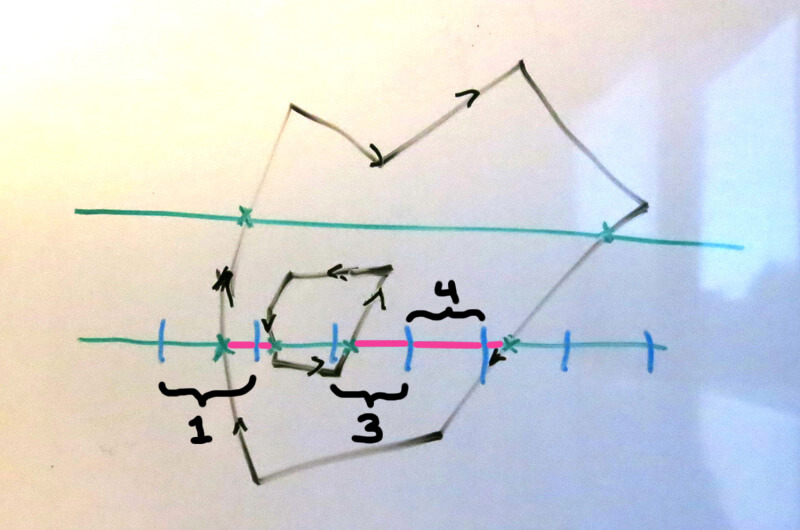
Here we can see that pixel #1 is about 25% pink, pixel 3 is about 80% pink, and pixel #4 is 100% pink. Thus we can determine that the (one-dimensional) anti-aliasing “coverage” of each of those pixels are 25%, 80%, and 100%.
这里我们可以看到像素1大概25%是粉色的,像素3大概80%是粉色的,像素4 100%是粉色的。所以我们就能确定这几个像素的一维抗锯齿“覆盖面积”分别是25%, 80%和100%。
The algorithm for computing this is identical to the previous algorithm; just the rule for how to fill pixels is different, as we have to track the fractional coverage of each “pixel” (line segment). Doing this is easy, though, since the edge crossings are always sorted left-to-right.
这个算法和上一个算法计算过程一样,只是填充规则不一样。我们需要记录每个像素(线段)的覆盖百分比。这么做很简单,因为交点都是从左向右排过序的。
stb_truetype 1.05 and earlier use an algorithm like the above. Rather than computing the above on every scanline, the software “oversamples” along the y axis, placing 5 “scanlines” per row of pixels, and letting the computation for each one contribute only 1/5th of the “coverage” value computed for each pixel. (For small characters, stb_truetype oversamples by a factor of 15; 5 and 15 are used because they divide 255 evenly, so they avoid the need for any fixup of the final sum, which must be 0..255.)
stb_truetype 1.05 和之前的版本使用了这样的算法。 它会在y轴上“过采样”,每行像素放置5条扫描线而不是一条,然后每条扫描线的计算贡献五分之一的覆盖面积。(针对小的字符,stb_truetype会进行15倍过采样。使用5和15是因为它们能被255整除,以免求和结果有误差,最终结果的范围是0到255。)
The “New” Algorithm “新”算法
I imagine this “new” algorithm I developed for stb_truetype 1.06 has already been published, although I was unable to find it anywhere (at least anywhere not behind a paywall).
我想我开发的这个 stb_truetype 1.06 “新”算法已经被发表过,但我并没有在任何可以免费获取的地方找到。
The core idea behind the algorithm, using signed areas, came from Maxim Shemanarev’s Anti-Grain Geometry source code; my coworker Fabian Giesen investigated that code to learn how the anti-aliased rasterizer worked, and came back with an incomplete understanding of the details, but a suspicion of that core idea. He shared the core idea with me, and I reworked a brand new algorithm from first principles based on it.
这个算法的核心概念是使用有符号面积,来自于Maxim Shemanarev的Anti-Grain Geometry源代码。我的同事Fabian Giesen通过研究这个代码来学习抗锯齿像素化的工作原理,得到了对实现细节不完全的理解和一点核心概念。他和我分享了这个核心概念,我基于这个概念通过第一性原理重新开发出了一个新的算法。
Edit: The idea itself appears to have reached AGG from FreeType which derived it from Ralph Levien’s LibArt; whether it came from him originally or was a published algorithm is unknown.
Edit: I have now found other write-ups of this algorithm: here and here; however, I think this article is still generally clearer and more thorough, and some of the ideas are handled slightly differently.
编辑:这个概念似乎是从Ralph Levien的LibArt传到了FreeType再到AGG(Anti-Grain Geometry)。不知道是Ralph Levien独创的还是当时已发表过的算法。
编辑:我现在发现了其他的介绍这个算法的文章:这里还有这里。但是我认为我这篇文章讲的更清楚更彻底,有些概念讲的也不太一样。
[FreeType font-rs Pathfinder用的也是这个算法。]
Signed area 有符号面积
A classic algorithm for measuring the area of a concave polygon is to compute the signed area of a number of triangles, one per edge, and sum them
一个经典的测量凹多边形面积的算法是计算每条边对应的三角形的有符号的面积之和。[每条边和左下角的原点组成一个三角形,绿色是正的面积,红色是负的面积。]

as this merely requires computing a cross-product per edge.
这样每条边只需计算一个叉积。
Perehaps less frequently used, but based on the same principle, one can measure the area as the sum of the signed area of a number of right-trapezoids:
可能不太常见,但基于同样的原理,我们也可以通过计算每条边对应的直角梯形的有符号的面积之和来测量面积。[每条边和x轴组成一个直角梯形]

The area of an axially-aligned right-trapezoid is particularly easy to compute, and these fit very well into the scanline framework.
与坐标轴平行的直角梯形的面积非常容易计算,而且能很好的加入到扫描线框架里。
Signed-area per pixel algorithm 有符号面积逐像素算法
Conceptually, the “new” AA algorithm computes the area of the entire polygon clipped to each pixel and uses that as the coverage for the pixel. Very little clipping is actually involved, and in practice most of the algorithm is nearly identical with the “active edge list” logic from the previous algorithm.
理论上,这个“新”抗锯齿算法计算整个多边形裁剪到每个像素的面积,并使用这个面积作为这个像素的覆盖面积。但实际上裁剪很少发生,算法的大部分和前面算法的“活跃边列表”逻辑几乎完全相同。
- Gather all of the directed edges into an array of edges
- Sort them by their topmost vertex
- Move a line down the polygon a scanline at a time (where a scanline is now 1-pixel tall, rather than infinitely thin), and for each scanline:
- Add to the “active edge list” any edges which have an uppermost vertex within this scanline, and store their x intersection with this scanline (because the edge list has been sorted by topmost y, edges from the edge list are always added in order)
- Remove from the active edge list any edge whose lowestmost vertex is above this scanline
- Compute the signed-area pixel coverage of the scanline (discussed below)
- Advance every active edge to the next scanline by computing their next x intersection (which just requires adding a constant dx/dy associated with the edge)
- 把所有有方向的边放到一个数组里
- 按靠上的顶点的y坐标对这些边进行排序
- 从上到下对多边形逐行扫描(现在扫描线为一个像素高,而不是无限细的),对于每条扫描线:
- 把所有靠上的顶点在这条扫描线之上的边加入“活跃边列表”,并存储它们和这条扫描线的交点的x坐标(由于边数组按靠上的顶点的y坐标排过序了,所以边是按顺序添加的)
- 从活跃边列表中移除所有靠下的顶点在这条扫描线之下的边
- 计算这条扫描线的有符号像素覆盖面积(会在下文讨论)
- 计算并更新活跃边列表里每条边对下一条扫描线的交点x坐标(只需加一个与这条边相关的常数dx/dy)
The differences here–beside the per-scanline processing discussed below–consist only of treating the scanline as 1-pixel tall (which slightly changes the rules for when edges are added and removed from the list), and omitting the need to sort the active edges from left to right.
除了下文讨论的逐扫描线处理过程,仅有的差别是把扫描线看作一个像素高,并省去对活跃边列表的排序。
Signed-area scanline rasterization 有符号面积扫描线像素化
The basic premise is we want to use signed-trapezoid areas to compute the pixel areas. The illustration above showed trapezoids filled to the bottom edge, but we’ll use trapezoids filled horizontally, to the right edge of the bitmap.
首要的前提是我们想用有符号的梯形面积来计算像素的覆盖面积。上图中梯形向下填充,但这里我们用梯形向右水平填充。
In other words, we want to compute something like the following (where color represents contribution from different edges, not the sign of the area):
换句话说,我们想计算下面的区域(颜色表示不同的边的贡献,而不是表示面积的正负):
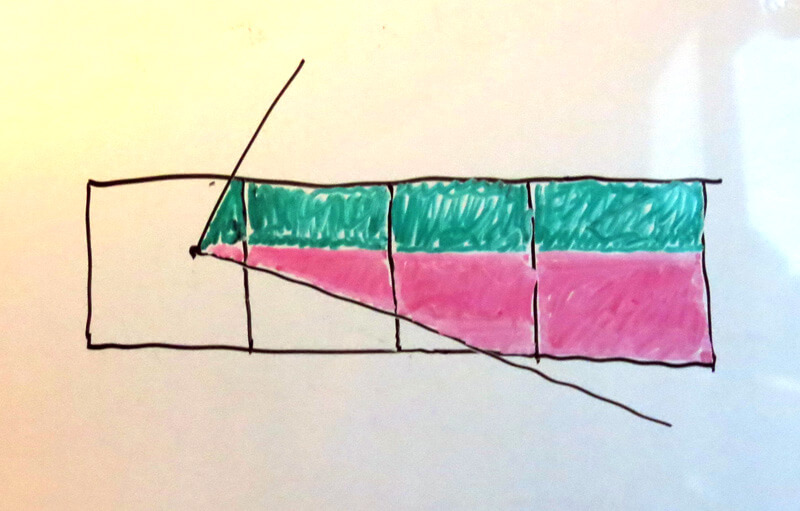
Here, each edge contributes to a right-extending trapezoid that covers multiple pixels, and theoretically extends infinitely far to the right. (The shapes within a single pixel may not be a trapezoid, e.g. the third pink shape, but it decomposes easily into a trapezoid and a rectangle.)
这里,每条边都对应了一个向右延伸覆盖多个像素的梯形,并且理论上可以向右延伸到无穷远。(单个像素里的形状可能不是梯形,例如第三个粉色的形状,但它可以很容易的分解成一个梯形和一个长方形。)
Later, we might close this polygon by drawing edges further to the right with the opposite signed area; these signed areas will extend rightwards, cancelling out the signed area in the pixels to the right of those new edges and producing 0-area per-pixel in those farther-right pixels.
然后,我们画右侧的边来闭合这个多边形,这些边对应负的有符号面积。这些面积向右延伸和左侧的边对应的面积抵消,使得在多边形右边的像素对应的有符号面积为零。
Note first that we aren’t trying to measure the area of the whole polygon, just the area coverage of each pixel, so we don’t actually care about the signed area of the trapezoid from the edge all the way to the right; rather we just care about the signed area within each pixel.
首先注意到我们不用测量整个多边形的面积,只用测量每个像素的覆盖面积,所以我们并不关心边对应的梯形的有符号面积,我们只关心每个像素里的有符号面积。
Note second that the area in each pixel covered by the trapezoid for a given edge varies in the pixels that the edge passes through, but is constant for all of the pixels further to the right. (E.g. the three green rectangles are the same area, and if there were more pixels to the right, they would have the same coverage as the rightmost pixel.)
其次注意到一条边对应的梯形对每个像素的覆盖面积对边所穿过的像素来讲是变化的,但对右边其他像素来说是固定的。(例如三个绿色的长方形面积相同,如果右边有更多的像素,也会有同样的覆盖面积。)
So the algorithm for the scanline is:
For each active edge:
For each pixel the edge intersects:
Compute the rightwards-trapezoid-ish area covering this pixel
Add the above area to the signed area for this pixel
For each pixel right of the edge:
Add the "height" of the edge within the scanline to the signed area for this pixel
所以扫描线的算法是:
For 每条活跃边:
For 每个这条边所相交的像素:
计算这个像素被梯形覆盖的面积
把这个面积加入这个像素的有符号面积
For 每个在这条边右侧的像素:
把这条边在扫描线内的的“高度”加入这个像素的有符号面积
The last line is because the areas to the right are always rectangles with width=1 pixel, so the area is the height*1, i.e. just height.
最后一行是因为右侧像素的覆盖区域为宽度为一的长方形,所以面积就是高度乘1,也就是高度。
Note that there is no need to traverse the active edges in any particular order, as the signed sums will be the same regardless, which is why the algorithm no longer keeps the active edges sorted horizontally.
注意我们不需要按任何顺序来遍历活跃边列表,因为有符号面积的和总是相同的,所以这个算法就不需要对活跃边列表进行水平方向的排序了。
Minimizing right-of-edge processing 减少对边右侧的处理
To achieve efficiency, it is necessary to implement the last two lines efficiently; accumulating into all of the pixels to the horizontal edge of the bitmap would be inefficient with many shapes; with e edges crossing a scanline that is n pixels wide, we might have to perfom as many as e*n add operations.
为了效率,我们需要高效的实现最后两行。当有很多形状时,累加所有的像素是很低效的。如果有e条边穿过了一条n像素宽的扫描线,我们需要进行e*n个加法操作。
To avoid this, we use the inverse of a cumulative sum table. If we make a table X and then later compute a cumulative sum S of X (where S[0] = X[0], S[n] = S[n-1] + X[n]), then we can create the effect of filling S[j..infinity] by simply writing a value into X[j]. Because everything is linear, we can likewise create the effect of adding a value height into S[j..infinity] by simply adding height into X[j].
为了避免这种情况,我们使用了一个“相反”的累加表。如果我们创建一个表X然后计算X的累加和表S(S[0] = X[0], S[n] = S[n-1] + X[n]),我们可以通过向X[j]加一个值来达到向S[j], S[j+1],…加一个值的效果。因为所有操作都是线性的,我们可以简单的通过向X[j]里加入高度来达到向S[j], S[j+1],…累加高度的效果。
In practice, we never compute the table S[]; the algorithm looks like this:
For one scanline:
1. Initialize arrays A, X to 0
2. Process e edges (see next section), summing areas into A & X
3. Let s = 0
4. For i = 0 to n do:
5. s = s + X[i]
6. a = A[i] + s
7. pixel[i] = 255 * a
实际上,我们不用计算表S[],算法是这样的:
For 每条扫描线:
1. 初始化数组A,X为0
2. 处理e条边(见下节),将面积加入A和X
3. s = 0
4. For i = 0 到 n:
5. s = s + X[i]
6. a = A[i] + s
7. pixel[i] = 255 * a
[A应该是边对相交像素的贡献,所以只算一次,X应该是边对右侧像素的贡献,所以是累加的。]
This makes one linear pass over the whole pixel array, rather than the as many as e passes as the naive algorithm would.
这样只用对整个像素数组遍历一次,而不是原始算法的e次。
Trapezoidal signed areas for pixels 梯形区域的有符号面积
The only thing missing from the algorithm above is how to compute the signed area coverage for any pixel which a given edge intersects. Computing this involves a large number of cases, which fortunately we can reduce to a small number of cases.
上述算法唯一缺失部分的是如何计算一条边穿过的像素的有符号覆盖面积。这个计算分为很多种情况,但我们可以将其归纳为少数几种情况。
First, to avoid complexity, we test whether the edge’s leftmost and rightmost x coordinates lie within the pixel range [0..n). In a font rasterizer, they normally always do; if they do not, we fall back to a less efficient algorithm that explicitly clip the edge’s trapezoid to each pixel.
首先,为了简单起见,我们会判断一条边左端和右端的x坐标是否在像素范围[0..n)内。进行字体的像素化时,一般都是在的。如果不在,我们就用一个效率更低的算法,直接的将边对应的梯形裁剪到每个像素内。
This means we never have to concern ourselves with the cases where the x coordinates lie outside the range of the A[] and X[] arrays, which reduces the cases to consider, i.e. removes the need for bounds-checking.
这意味着我们不用考虑x坐标在A[]和X[]数组范围外的情况,减少了需要考虑的境况,也就是消除了边界检查。
A given edge can have at most two intersections with a pixel, but those intersections can be with various combinations of the top and bottom and the sides. Additionally, an edge may have only one intersection (with any of the 4 sides), or no intersections at all.
一条边最多和一个像素有两个交点,但这两个交点的位置可能在这个像素的上边,下边或者左右两边。此外,一条边与一个像素也可能只有一个交点(与像素四个边的任一边相交),或者没有交点。
[一条边的一个端点在这个像素里面,一个端点在这个像素外面,则只有一个交点;一条边的两个端点都在这个像素里面,则没有交点。]
To avoid this complexity, we can treat an intersection with the top the same as the top vertex lying within the pixel, and an intersection with the bottom the same as the bottom vertex lying within the pixel. The math is not identical as is, but we avoid a case explosion by handling them as the same kind of cases, by simply computing relative to the clipped endpoints, whether those be at the edges or somewhere inside.
为了简单起见,我们把一条边与像素上边有交点的情况当作这条边的上端在像素内来处理,把一条边与像素下边有交点的情况当作这条边的下端在像素内来处理。虽然计算并不完全一样,但可以当作同一种情况来处理,以免要处理情况太多。我们可以按照裁剪后的端点来进行计算,而不用管它们是在像素里面还是在像素的边缘。
[对单个像素来说,只需考虑一条边在这个像素里面的部分,相当于把一条边延伸出像素外的部分裁剪掉,裁剪后端点就在像素里面了。]
Case 1: The edge touches one pixel 第一种情况:边只穿过一个像素
[确切的说,是在一条水平的扫描线内,一条边只经过了一个像素]
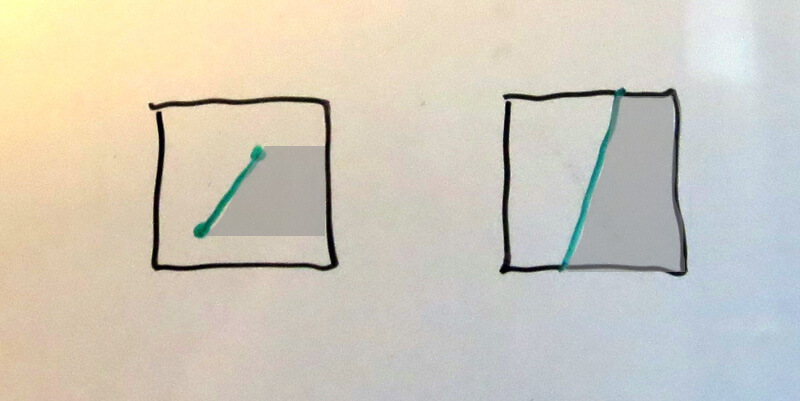
Here two of the four possible versions of this case are shown (the other two intersect only at the top or the bottom).
这里只显示了四种可能情况中的两种。(另外两种是只和像素的上边或者下边相交。)
The calculation of the trapezoidal area covered to the right of these edges is straightforward. If the x coordinates are measured from the right side of the pixel, then the trapezoid’s area is the height times the average of the two x-coordinates.
我们可以很容易的计算出这样的边的右侧梯形区域面积。如果x坐标是以像素右侧为原点来表示的话,那么梯形面积就是高度乘以两个端点x坐标的平均值。
Case 2: The edge touches two or more pixels 第二种情况:边穿过多个像素
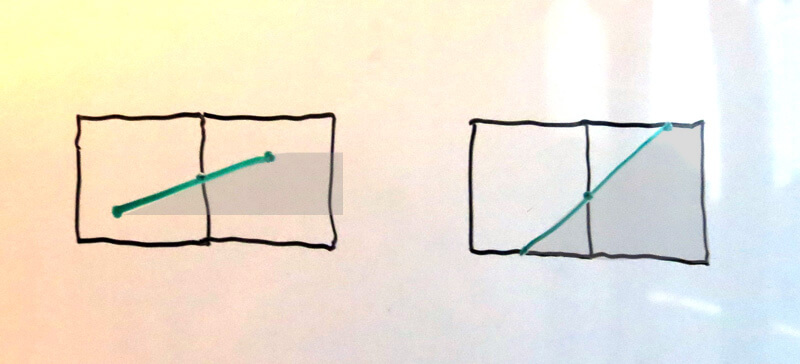
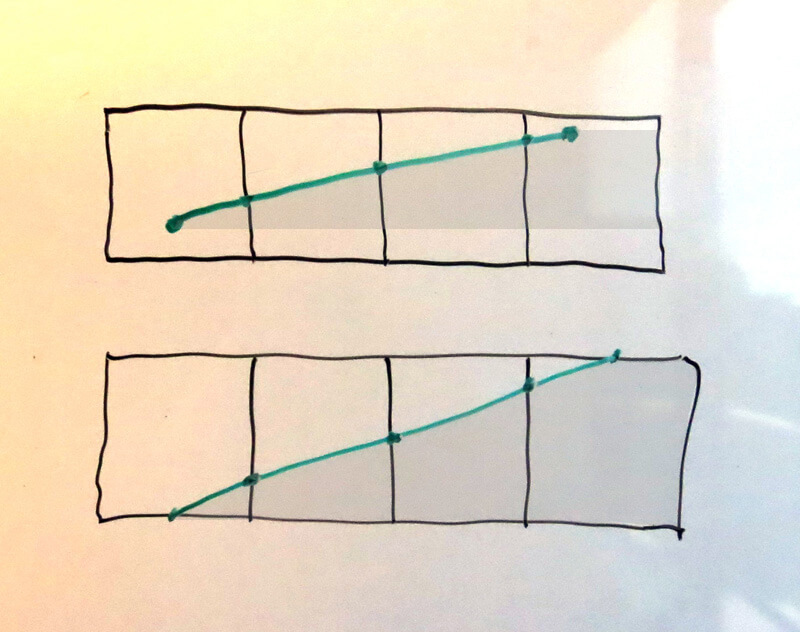
Computing the area covered by the right-extending trapezoids for these edges isn’t much harder. In each case we must compute the intersections with the left and right sides of the pixels to evaluate the trapezoid formula mentioned above. However, once we compute the leftmost pixel’s right-side intersection, the following intersections all increase linearly; in the same way that the vertical scanning algorithm simply steps the current x by dx/dy, so too can we simply step the y value of the side intersection by dy/dx.
计算这些边的右侧梯形区域面积也不难。在每种情况下,我们必须计算边与各个像素左侧和右侧的交点,然后套用上面提到的梯形面积公式。然而一旦我们计算出了一条边与最左边的像素的右边的交点,那么接下来的交点位置都是线性的增加的。就像水平扫描线算法通过加上一个dx/dy来更新x坐标一样,这里我们也可以通过加上一个dy/dx来更新侧边交点的y坐标。
But, even simpler than that, the area covered of each successive pixel itself increases linearly; that is, if there are 5 pixels covered, the area of pixels #1 and #5 are “arbitrary”, but the difference between the area of pixel #2 and pixel #3 is the same as the difference between the area of pixel #3 and pixel #4; and that difference itself is also dy/dx.
但是其实可以更简单,因为每个相邻像素的覆盖面积也是线性的增加的,也就是说,如果有5个像素,第一个像素和第五个像素的面积是“任意的”,但第二个像素和第三个像素的差值等于第三个像素和第四个像素的差值,这个差值就是dy/dx。
Thus, handling this case requires:
- Compute the intersection of the edge with right side of the leftmost pixel
- Compute the area of the triangle in the leftmost pixel
- Compute the area of the trapezoid in the second pixel
- Process successive pixels, adding dy/dx to the area
- Compute the intersection of the edge with left side of the rightmost pixel
- Compute the area of the shape in the rightmost pixel
although this is not exactly how the math is computed in stb_truetype.h.
所以说,处理这种情况需要:
- 计算这条边与最左侧像素右边的交点
- 计算最左侧像素的三角形覆盖面积
- 计算第二个像素的梯形覆盖面积
- 处理接下来的像素,面积加上dy/dx
- 计算这条边与最右侧像素左边的交点
- 计算最右侧像素的覆盖面积
其实stb_truetype的计算过程并不完全是这样的。
Case 3: Edges sloping in the opposite direction 第三种情况:相反方向斜率的边
Case 2 is described as processing the pixels left-to-right, but the edges may slope opposite the direction shown in case 2, which can lead to incorrect math to compute e.g. step 6. However, we note that the area covered in each pixel in the shape below is identical to that covered in the second shape.
第二种情况描述了从左至右处理像素,但边的斜率可能和第二种情况里展示的相反,那么计算结果就会不正确,例如第6步。但是我们可以看到各个像素被下面两个形状所覆盖的面积是完全一样的。
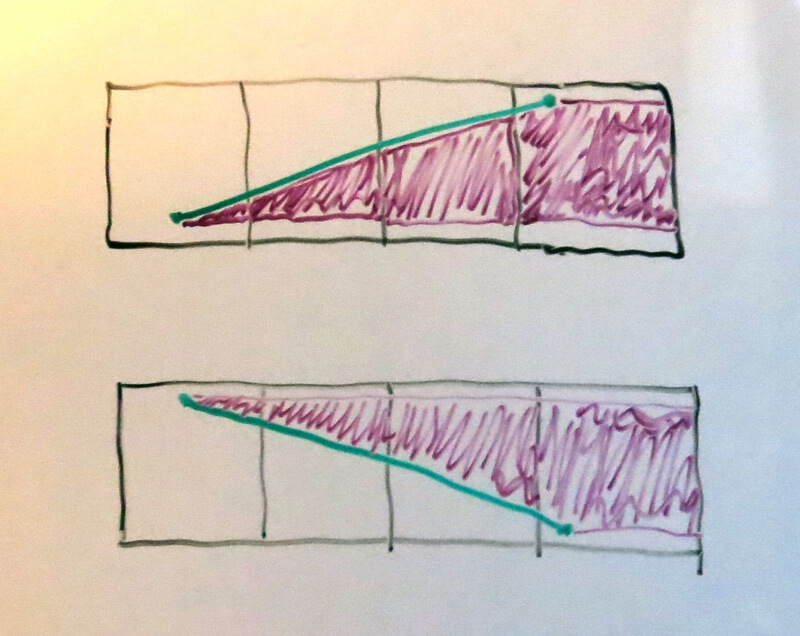
Thus, we can write Case 2 strictly in terms of e.g. edges that slope NE-SW (regardless of direction); to handle edges that slope NW-SE, we simply flip the edge vertically (not swapping the endpoints, but actually flipping the y-coordinates and negating the slopes), and then use Case 2.
因此我们可以假定边的斜率是正的,按第二种情况计算。如果边的斜率为负,我们垂直翻转这条边(不是交换端点,而是翻转y坐标反转斜率),再应用第二种情况。
Alternatively, it may be possible to simply use the same code for both slopes, through judicious usage of absolute-value operations when computing the areas, and this may be faster as well, but I didn’t try it.
或者也可以用同样的代码处理这两种斜率,但要正确的使用绝对值操作来计算面积,这样可能会更高效,但我没试过。
Sample code for Case 2 & 3 第二第三种情况的代码示例
This is the code in stb_truetype for Case 2 & 3, which actually converts everything into NW-SE slopes, which is the opposite of the Case 2 illustrations.
这是stb_truetype处理第二第三种情况的代码示例,它把所有边都转换成负斜率的边,与第二种情况所说明的正好相反。
{
int x,x1,x2;
float y_crossing, step, sign, area;
// covers 2+ pixels
if (x_top > x_bottom) {
// flip scanline vertically; signed area is the same
float t;
y0 = y_bottom - (y0 - y_top);
y1 = y_bottom - (y1 - y_top);
t = y0, y0 = y1, y1 = t;
t = x_bottom, x_bottom = x_top, x_top = t;
dx = -dx;
dy = -dy;
t = x0, x0 = xb, xb = t;
}
x1 = (int) x_top;
x2 = (int) x_bottom;
// compute intersection with y axis at x1+1
y_crossing = (x1+1 - x0) * dy + y_top;
sign = e->direction;
// area of the rectangle covered from y0..y_crossing
area = sign * (y_crossing-y0);
// area of the triangle (x_top,y0), (x+1,y0), (x+1,y_crossing)
scanline[x1] += area * (1-((x_top - x1)+(x1+1-x1))/2);
step = sign * dy;
for (x = x1+1; x < x2; ++x) {
scanline[x] += area + step/2;
area += step;
}
y_crossing += dy * (x2 - (x1+1));
scanline[x2] += area + sign * (1-((x2-x2)+(x_bottom-x2))/2) * (y1-y_crossing);
scanline_fill[x2] += sign * (y1-y0);
}
Performance 效率
This algorithm runs slightly faster than the 5-times oversampled algorithm used in previous versions of stb_truetype.h. Since the 5-times-oversampled algorithm has to process 5 times as many scanlines, this may seem less speedup than expected; however, despite having the same overall framework, it has to do a lot more work.
这个算法比原先版本的stb_truetype的5倍过采样算法稍快。这个算法处理的扫描线是5倍过采样要方法的五分之一,但速度却并没有很大提升。这是因为尽管有着相同的框架,这个算法要做更多的计算工作。
The performance-relative differences are:
- Precomputes dy/dx per edge (to avoid having to do multiple divides later)
- Needs to compute two y-intersections per horizontal-ish edge (divide-free)
- Trapezoid math computation (two or three multiplies, including one for sign)
- Still sorts initial edges vertically, but doesn’t need to sort active edges horizontally
性能相关的差异有:
- 预先计算每条边的dy/dx(避免多次进行除法)
- 每条水平的边需要计算两个交点y坐标(不用除法)[这一条没看明白。。]
- 梯形面积计算(两或三个乘法,包括一个为了符号的)
- 仍然需要开始时对边进行垂直方向排序,但不需要对活跃边进行水平方向排序
In particular, all of the code above for Case 2 is handled with oversampling by simply oversampling using the normal trivial code, whereas Case 2 involves a lot of processing per edge (although the per-pixel costs are fairly low for edges that cover many pixels).
特别一提,针对第二种情况,原先的代码用简单的过采样来进行处理,而这个算法包含了许多对每条边的处理(尽管当边穿过很多像素时,平均每个像素的开销很小)。
Limitations 算法局限性
The algorithm exactly computes the area of polygons intersecting a given pixel. However, if multiple overlapping polygons intersect the same pixel, it is measuring the area of the polygons, not the fraction of the pixel that is covered.
这个算法精确的计算多边形与一个像素相交的面积。然而如果多个重叠的多边形与同一个像素相交,这个算法会计算这些多边形的面积,而不是像素被覆盖的部分的面积。
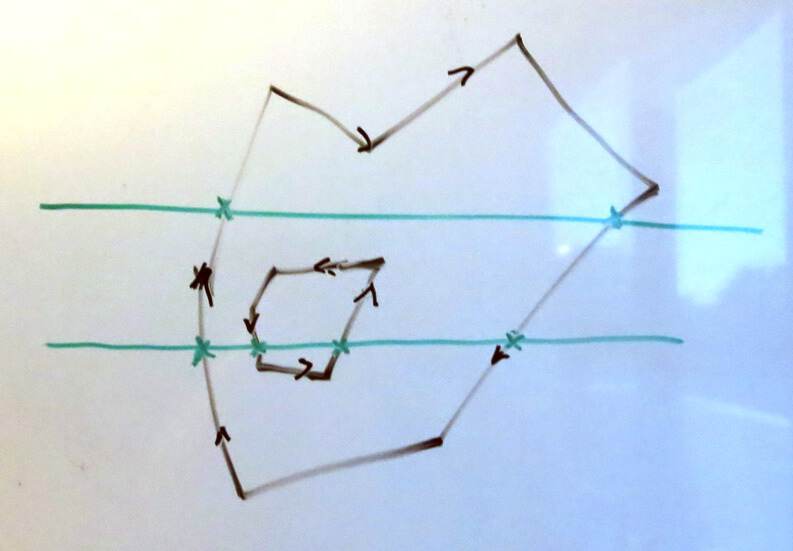
For example, if the entire shape above were within a single pixel, the algorithm would correctly compute the coverage of the pixel. However, if the interior hole were wound in the opposite direction, it would cease to be a hole, and the entire shape would be filled. In this case, the new algorithm would report the signed area of the shape as the sum of the outer shape and the inner shape, when the actual coverage of the pixel would simply be the area of the outer shape (the area covered by the inner shape is already counted in the outer shape’s area, so that area is double-counted).
例如,如果整个形状都是在一个像素内,这个算法会正确的计算像素的覆盖面积。然而,如果内部的空洞是另外的一个方向,它就不是一个洞了,整个形状都需要被填充。这种情况下,新算法就会认为这个形状的有符号面积为外面的形状的面积和里面的形状的面积的和,而真正的像素覆盖面积其实是外面的形状的面积(内部形状的面积已经包含在外部形状的面积内了,所以这个区域被算了两遍)。
In practice large double-covered areas will be opaque, and the double-counting will be clamped to 100% coverage and have no effect. I believe in practice most errors due to double-counting will occur at concave corners where two shapes meet, leading to a single darker pixel in those areas. I believe that excessive darkening of concave corners will be unobjectionable.
实际情况下,大块的多重覆盖的面积是被完全覆盖的,即使算了两遍还是会被截断成100%的被覆盖,没有实际影响。我认为实际情况下大部分由于算了两遍而造成的误差会发生在两个形状重叠的交叉角落,使一个像素更深一点。我认为这个颜色过深的角落没什么影响。
It would be possible for someone to author a font where every character has the whole shape repeated twice or more; a traditional rasterizer, including the old stb_truetype one, would draw this identically to there only being a single copy of the shape, whereas the new one would draw all pixels with twice as much AA coverage (clamped), which would be an objectionable artifact. I do not expect to find fonts doing this in the wild, though. If it does turn out to be objectionable, the stb_truetype still has the old rasterizer available on a compile-time switch.
有可能有人创作了一个字体,每个字符的形状都重复画了一次或者多次。一个传统的渲染器,包括老的stb_truetype,能像正常没有重复的形状一样画,但新的算法会产生两倍或者多倍的抗锯齿覆盖面积,造成不好的缺陷。但我觉得市面上并没有这样的字体。如果真有这种问题,stb_truetype也通过一个编译选项提供了老的渲染器。